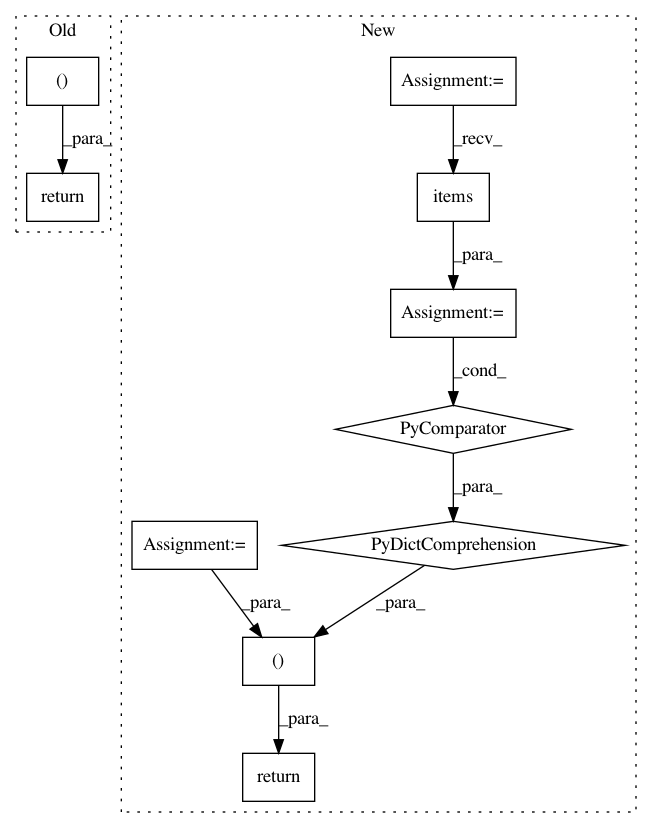
action = self._f_prob([observation])
action = self.action_space.unflatten(action)
return action, dict()
def get_actions(self, observations):
Get multiple actions from this policy for the input observations.
After Change
actions, agent_infos = self.get_actions([observation])
action = actions[0]
return action, {k: v[0] for k, v in agent_infos.items()}
def get_actions(self, observations):
Get multiple actions from this policy for the input observations.