self.log_reshaped_return = [0] * self.num_procs
self.log_num_frames = [0] * self.num_procs
def collect_experiences(self):
Collects rollouts and computes advantages.
Runs several environments concurrently. The next actions are computed
in a batch mode for all environments at the same time. The rollouts
and advantages from all environments are concatenated together.
Returns
-------
exps : DictList
Contains actions, rewards, advantages etc as attributes.
Each attribute, e.g. `exps.reward` has a shape
(self.num_frames_per_proc * num_envs, ...). k-th block
of consecutive `self.num_frames_per_proc` frames contains
data obtained from the k-th environment. Be careful not to mix
data from different environments!
logs : dict
Useful stats about the training process, including the average
reward, policy loss, value loss, etc.
for i in range(self.num_frames_per_proc):
// Do one agent-environment interaction
preprocessed_obs = self.preprocess_obss(self.obs, device=self.device)
with torch.no_grad():
if self.acmodel.recurrent:
dist, value, memory = self.acmodel(preprocessed_obs, self.memory * self.mask.unsqueeze(1))
else:
dist, value = self.acmodel(preprocessed_obs)
action = dist.sample()
obs, reward, done, _ = self.env.step(action.cpu().numpy())
// Update experiences values
self.obss[i] = self.obs
self.obs = obs
if self.acmodel.recurrent:
self.memories[i] = self.memory
self.memory = memory
self.masks[i] = self.mask
self.mask = 1 - torch.tensor(done, device=self.device, dtype=torch.float)
self.actions[i] = action
self.values[i] = value
if self.reshape_reward is not None:
self.rewards[i] = torch.tensor([
self.reshape_reward(obs_, action_, reward_, done_)
for obs_, action_, reward_, done_ in zip(obs, action, reward, done)
], device=self.device)
else:
self.rewards[i] = torch.tensor(reward, device=self.device)
self.log_probs[i] = dist.log_prob(action)
// Update log values
self.log_episode_return += torch.tensor(reward, device=self.device, dtype=torch.float)
self.log_episode_reshaped_return += self.rewards[i]
self.log_episode_num_frames += torch.ones(self.num_procs, device=self.device)
for i, done_ in enumerate(done):
if done_:
self.log_done_counter += 1
self.log_return.append(self.log_episode_return[i].item())
self.log_reshaped_return.append(self.log_episode_reshaped_return[i].item())
self.log_num_frames.append(self.log_episode_num_frames[i].item())
self.log_episode_return *= self.mask
self.log_episode_reshaped_return *= self.mask
self.log_episode_num_frames *= self.mask
// Add advantage and return to experiences
preprocessed_obs = self.preprocess_obss(self.obs, device=self.device)
with torch.no_grad():
if self.acmodel.recurrent:
_, next_value, _ = self.acmodel(preprocessed_obs, self.memory * self.mask.unsqueeze(1))
else:
_, next_value = self.acmodel(preprocessed_obs)
for i in reversed(range(self.num_frames_per_proc)):
next_mask = self.masks[i+1] if i < self.num_frames_per_proc - 1 else self.mask
next_value = self.values[i+1] if i < self.num_frames_per_proc - 1 else next_value
next_advantage = self.advantages[i+1] if i < self.num_frames_per_proc - 1 else 0
delta = self.rewards[i] + self.discount * next_value * next_mask - self.values[i]
self.advantages[i] = delta + self.discount * self.gae_lambda * next_advantage * next_mask
// Define experiences:
// the whole experience is the concatenation of the experience
// of each process.
// In comments below:
// - T is self.num_frames_per_proc,
// - P is self.num_procs,
// - D is the dimensionality.
exps = DictList()
exps.obs = [self.obss[i][j]
for j in range(self.num_procs)
for i in range(self.num_frames_per_proc)]
if self.acmodel.recurrent:
// T x P x D -> P x T x D -> (P * T) x D
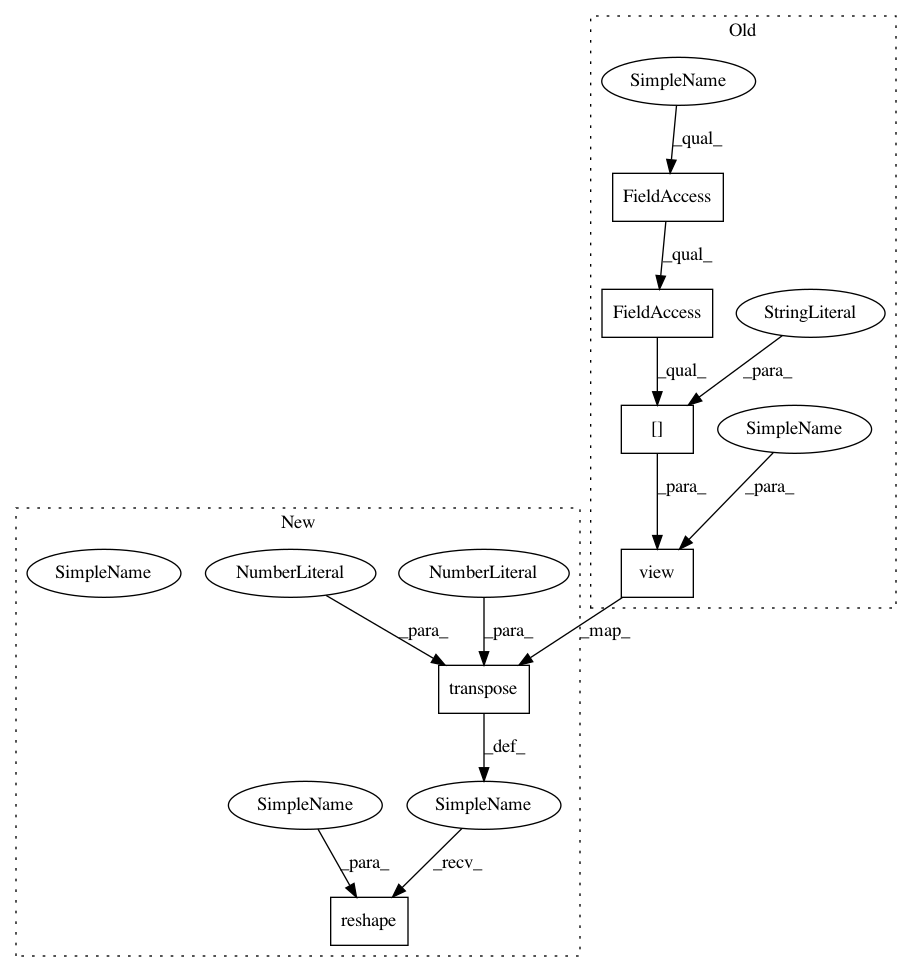
exps.memory = self.memories.transpose(0, 1).reshape(-1, *self.memories.shape[2:])
// T x P -> P x T -> (P * T) x 1
exps.mask = self.masks.transpose(0, 1).reshape(-1).unsqueeze(1)
// for all tensors below, T x P -> P x T -> P * T
exps.action = self.actions.transpose(0, 1).reshape(-1)
exps.value = self.values.transpose(0, 1).reshape(-1)
exps.reward = self.rewards.transpose(0, 1).reshape(-1)
exps.advantage = self.advantages.transpose(0, 1).reshape(-1)
exps.returnn = exps.value + exps.advantage
exps.log_prob = self.log_probs.transpose(0, 1).reshape(-1)
// Preprocess experiences
exps.obs = self.preprocess_obss(exps.obs, device=self.device)