x_init = -(1./H.squeeze(2))*q
else:
H_lu = H.lu()
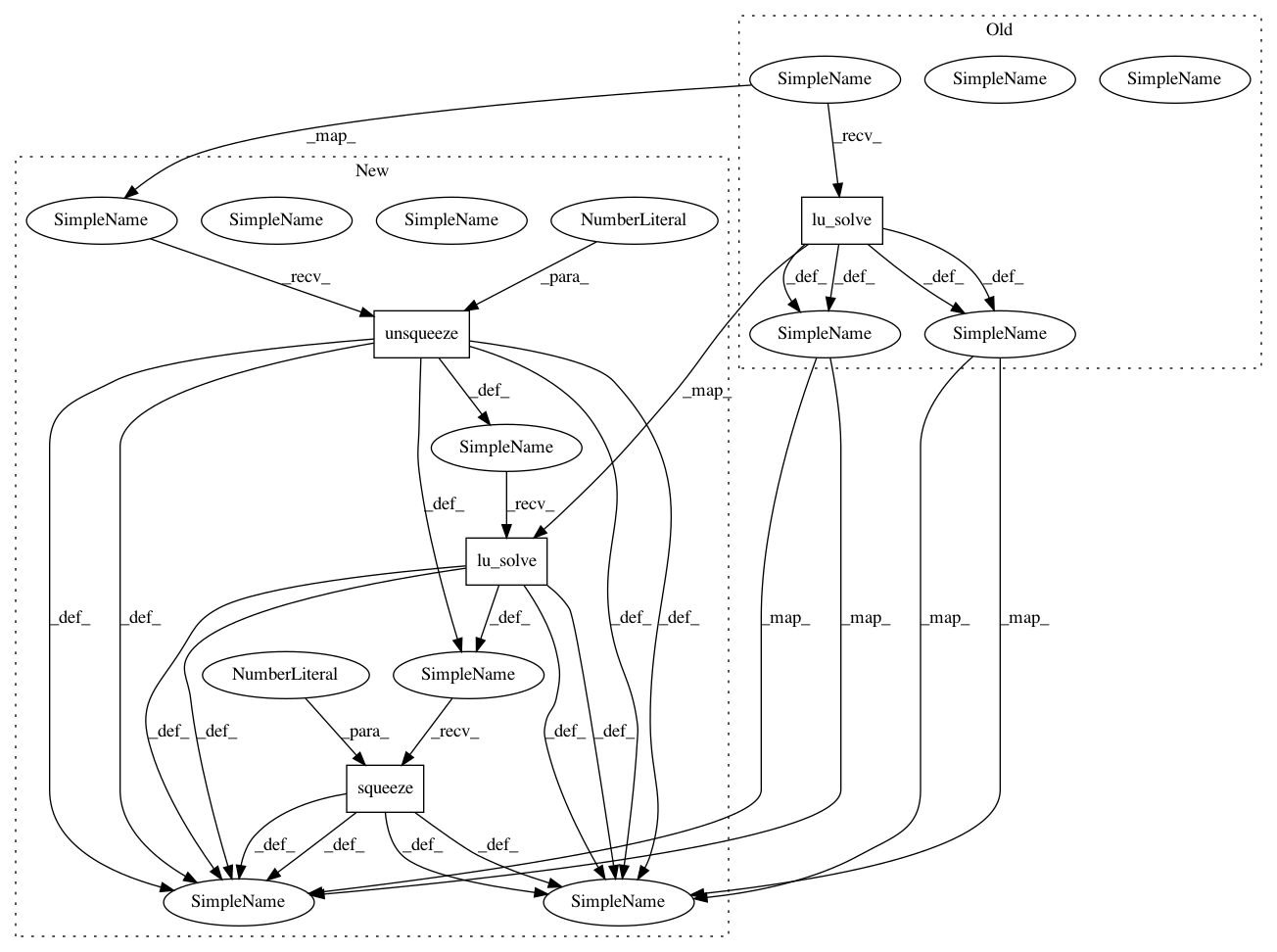
x_init = -q.lu_solve(*H_lu) // Clamped in the x assignment.
else:
x_init = x_init.clone() // Don"t over-write the original x_init.
x = util.eclamp(x_init, lower, upper)
// Active examples in the batch.
J = torch.ones(n_batch).type_as(x).byte()
for i in range(n_iter):
g = util.bmv(H, x) + q
Ic = ((x == lower) & (g > 0)) | ((x == upper) & (g < 0))
If = 1-Ic
if If.is_cuda:
Hff_I = util.bger(If.float(), If.float()).type_as(If)
not_Hff_I = 1-Hff_I
Hfc_I = util.bger(If.float(), Ic.float()).type_as(If)
else:
Hff_I = util.bger(If, If)
not_Hff_I = 1-Hff_I
Hfc_I = util.bger(If, Ic)
g_ = g.clone()
g_[Ic] = 0.
H_ = H.clone()
H_[not_Hff_I] = 0.0
H_ += pnqp_I
if n == 1:
dx = -(1./H_.squeeze(2))*g_
else:
H_lu_ = H_.lu()
dx = -g_.lu_solve(*H_lu_)
J = torch.norm(dx, 2, 1) >= 1e-4
m = J.sum().item() // Number of active examples in the batch.
if m == 0:
return x, H_ if n == 1 else H_lu_, If, i
alpha = torch.ones(n_batch).type_as(x)
decay = 0.1
max_armijo = GAMMA
count = 0
while max_armijo <= GAMMA and count < 10:
// Crude way of making sure too much time isn"t being spent
// doing the line search.
// assert count < 10
maybe_x = util.eclamp(x+torch.diag(alpha).mm(dx), lower, upper)
armijos = (GAMMA+1e-6)*torch.ones(n_batch).type_as(x)
armijos[J] = (obj(x)-obj(maybe_x))[J]/util.bdot(g, x-maybe_x)[J]
I = armijos <= GAMMA
alpha[I] *= decay
max_armijo = torch.max(armijos)
count += 1
x = maybe_x
// TODO: Maybe change this to a warning.
print("[WARNING] pnqp warning: Did not converge")
After Change
x_init = -(1./H.squeeze(2))*q
else:
H_lu = H.lu()
x_init = -q.unsqueeze(2).lu_solve(*H_lu).squeeze(2) // Clamped in the x assignment.
else:
x_init = x_init.clone() // Don"t over-write the original x_init.
x = util.eclamp(x_init, lower, upper)
// Active examples in the batch.
J = torch.ones(n_batch).type_as(x).byte()
for i in range(n_iter):
g = util.bmv(H, x) + q
// TODO: Could clean up the types here.
Ic = (((x == lower) & (g > 0)) | ((x == upper) & (g < 0))).float()
If = 1-Ic
if If.is_cuda:
Hff_I = util.bger(If.float(), If.float()).type_as(If)
not_Hff_I = 1-Hff_I
Hfc_I = util.bger(If.float(), Ic.float()).type_as(If)
else:
Hff_I = util.bger(If, If)
not_Hff_I = 1-Hff_I
Hfc_I = util.bger(If, Ic)
g_ = g.clone()
g_[Ic.bool()] = 0.
H_ = H.clone()
H_[not_Hff_I.bool()] = 0.0
H_ += pnqp_I
if n == 1:
dx = -(1./H_.squeeze(2))*g_
else:
H_lu_ = H_.lu()
dx = -g_.unsqueeze(2).lu_solve(*H_lu_).squeeze(2)
J = torch.norm(dx, 2, 1) >= 1e-4
m = J.sum().item() // Number of active examples in the batch.
if m == 0:
return x, H_ if n == 1 else H_lu_, If, i
alpha = torch.ones(n_batch).type_as(x)
decay = 0.1
max_armijo = GAMMA
count = 0
while max_armijo <= GAMMA and count < 10:
// Crude way of making sure too much time isn"t being spent
// doing the line search.
// assert count < 10
maybe_x = util.eclamp(x+torch.diag(alpha).mm(dx), lower, upper)
armijos = (GAMMA+1e-6)*torch.ones(n_batch).type_as(x)
armijos[J] = (obj(x)-obj(maybe_x))[J]/util.bdot(g, x-maybe_x)[J]
I = armijos <= GAMMA
alpha[I] *= decay
max_armijo = torch.max(armijos)
count += 1
x = maybe_x
// TODO: Maybe change this to a warning.
print("[WARNING] pnqp warning: Did not converge")