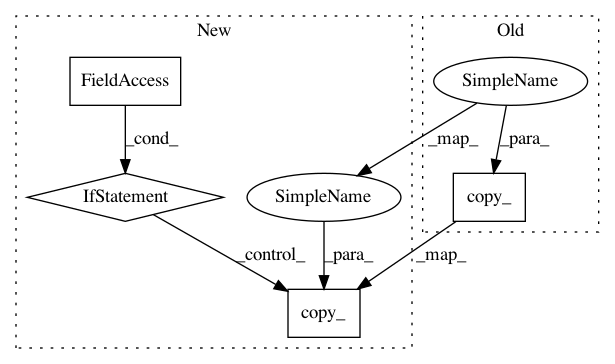
def forward(self, bn_weight, bn_bias, *inputs):
// Save the current BN statistics for later
prev_running_mean = self.running_mean.clone()
prev_running_var = self.running_var.clone()
// Create tensors that use shared allocations
// One for the concatenation output (bn_input)
// One for the ReLU output (relu_output)
all_num_channels = [input.size(1) for input in inputs]
size = list(inputs[0].size())
for num_channels in all_num_channels[1:]:
size[1] += num_channels
storage = self.shared_allocation_1.storage_for(inputs[0])
bn_input_var = Variable(type(inputs[0])(storage).resize_(size), volatile=True)
relu_output = type(inputs[0])(storage).resize_(size)
// Create variable, using existing storage
torch.cat(inputs, dim=1, out=bn_input_var.data)
// Do batch norm
bn_weight_var = Variable(bn_weight, volatile=True)
bn_bias_var = Variable(bn_bias, volatile=True)
bn_output_var = F.batch_norm(bn_input_var, self.running_mean, self.running_var,
bn_weight_var, bn_bias_var, training=self.training,
momentum=self.momentum, eps=self.eps)
// Do ReLU - and have the output be in the intermediate storage
torch.clamp(bn_output_var.data, 0, 1e100, out=relu_output)
self.save_for_backward(bn_weight, bn_bias, *inputs)
// restore the BN statistics for later
self.running_mean.copy_(prev_running_mean)
self.running_var.copy_(prev_running_var)
return relu_output
def prepare_backward(self):
bn_weight, bn_bias = self.saved_tensors[:2]
After Change
if self.training:
// Save the current BN statistics for later
prev_running_mean = self.running_mean.clone()
prev_running_var = self.running_var.clone()
// Create tensors that use shared allocations
// One for the concatenation output (bn_input)
// One for the ReLU output (relu_output)
all_num_channels = [input.size(1) for input in inputs]
size = list(inputs[0].size())
for num_channels in all_num_channels[1:]:
size[1] += num_channels
storage = self.shared_allocation_1.storage_for(inputs[0])
bn_input_var = Variable(type(inputs[0])(storage).resize_(size), volatile=True)
relu_output = type(inputs[0])(storage).resize_(size)
// Create variable, using existing storage
torch.cat(inputs, dim=1, out=bn_input_var.data)
// Do batch norm
bn_weight_var = Variable(bn_weight, volatile=True)
bn_bias_var = Variable(bn_bias, volatile=True)
bn_output_var = F.batch_norm(bn_input_var, self.running_mean, self.running_var,
bn_weight_var, bn_bias_var, training=self.training,
momentum=self.momentum, eps=self.eps)
// Do ReLU - and have the output be in the intermediate storage
torch.clamp(bn_output_var.data, 0, 1e100, out=relu_output)
self.save_for_backward(bn_weight, bn_bias, *inputs)
if self.training:
// restore the BN statistics for later
self.running_mean.copy_(prev_running_mean)
self.running_var.copy_(prev_running_var)
return relu_output
def prepare_backward(self):
bn_weight, bn_bias = self.saved_tensors[:2]