return tuple(reader.get_column_name(idx) for idx in range(self.total_genes) if reader.get_column_name(idx) != INDEX_NAME)
def load_full(self) -> pd.DataFrame:
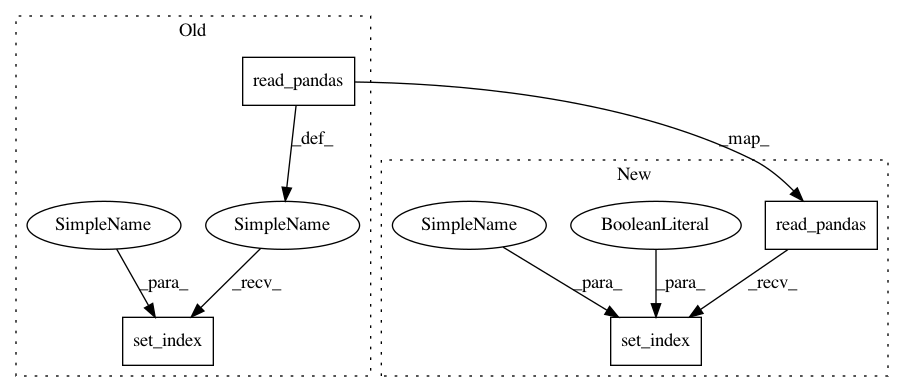
return FeatherReader(self._fname).read_pandas().set_index(INDEX_NAME)
def load(self, gs: Type[GeneSignature]) -> pd.DataFrame:
return FeatherReader(self._fname).read_pandas(columns=(INDEX_NAME,) + gs.genes).set_index(INDEX_NAME)
After Change
return tuple(reader.get_column_name(idx) for idx in range(self.total_genes) if reader.get_column_name(idx) != INDEX_NAME)
def load_full(self) -> pd.DataFrame:
df = FeatherReader(self._fname).read_pandas()
// Avoid copying the whole dataframe by replacing the index in place.
// This makes loading a database twice as fast in case the database file is already in the filesystem cache.
df.set_index(INDEX_NAME, inplace=True)
return df
def load(self, gs: Type[GeneSignature]) -> pd.DataFrame:
df = FeatherReader(self._fname).read_pandas(columns=(INDEX_NAME,) + gs.genes)