be the decoded sequence)
parser.add_argument("-beam_size", type=int, default=5,
help="Beam size")
parser.add_argument("-batch_size", type=int, default=30,
help="Batch size")
parser.add_argument("-max_sent_length", type=int, default=100,
help="Maximum sentence length.")
parser.add_argument("-replace_unk", action="store_true",
help=Replace the generated UNK tokens with the
source token that had highest attention weight. If
phrase_table is provided, it will lookup the
identified source token and give the corresponding
target token. If it is not provided(or the identified
source token does not exist in the table) then it
will copy the source token)
parser.add_argument("-verbose", action="store_true",
help="Print scores and predictions for each sentence")
parser.add_argument("-attn_debug", action="store_true",
help="Print best attn for each word")
parser.add_argument("-dump_beam", type=str, default="",
help="File to dump beam information to.")
parser.add_argument("-n_best", type=int, default=1,
help=If verbose is set, will output the n_best
decoded sentences)
parser.add_argument("-gpu", type=int, default=-1,
help="Device to run on")
// Options most relevant to summarization.
parser.add_argument("-dynamic_dict", action="store_true",
help="Create dynamic dictionaries")
parser.add_argument("-share_vocab", action="store_true",
help="Share source and target vocabulary")
// Options most relevant to speech.
parser.add_argument("-sample_rate", type=int, default=16000,
help="Sample rate.")
parser.add_argument("-window_size", type=float, default=.02,
help="Window size for spectrogram in seconds")
parser.add_argument("-window_stride", type=float, default=.01,
help="Window stride for spectrogram in seconds")
parser.add_argument("-window", default="hamming",
help="Window type for spectrogram generation")
// Alpha and Beta values for Google Length + Coverage penalty
// Described here: https://arxiv.org/pdf/1609.08144.pdf, Section 7
parser.add_argument("-alpha", type=float, default=0.,
help=Google NMT length penalty parameter
(higher = longer generation))parser.add_argument("-beta", type=float, default=-0.,
help=Coverage penalty parameter)
def add_md_help_argument(parser):
parser.add_argument("-md", action=MarkdownHelpAction,
After Change
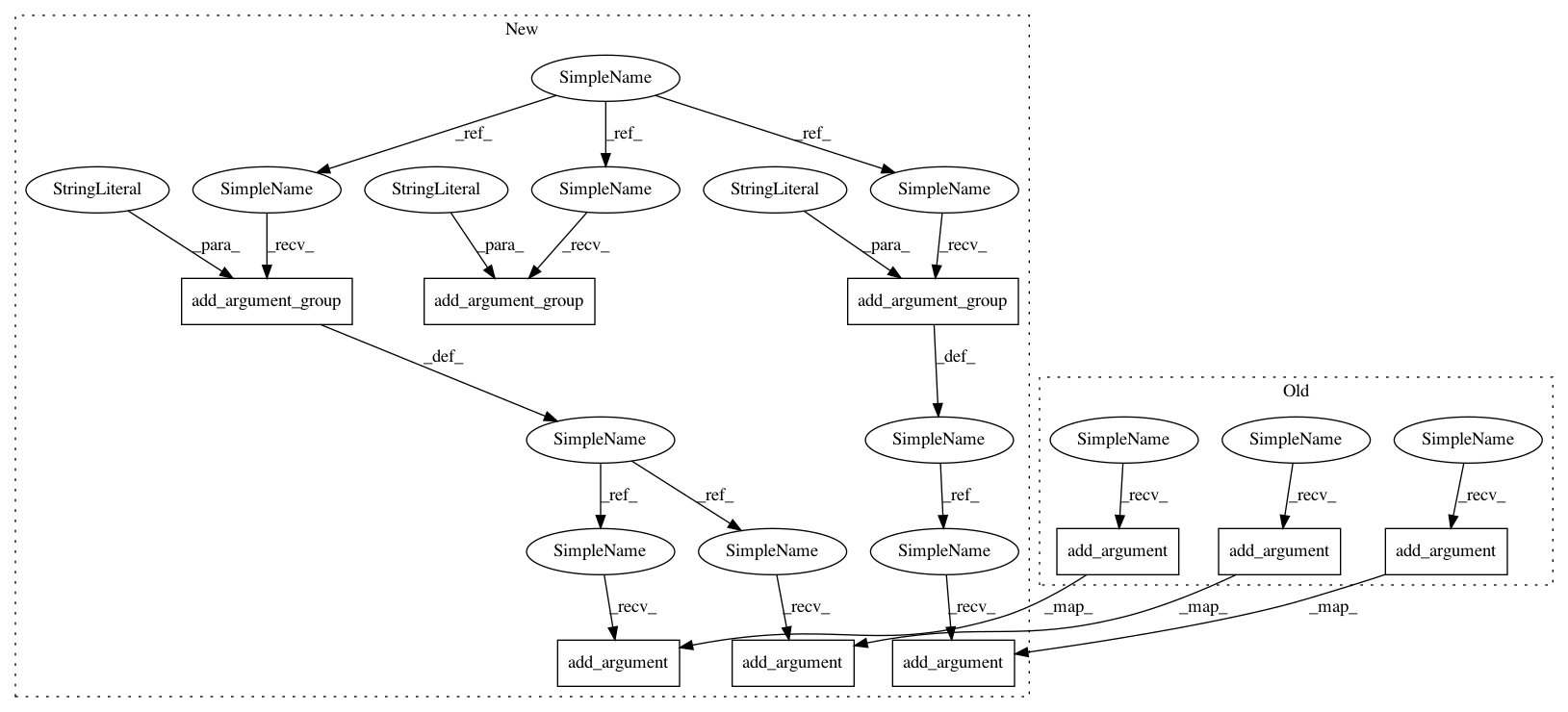
def translate_opts(parser):
group = parser.add_argument_group("Model")
group.add_argument("-model", required=True,
help="Path to model .pt file")
group = parser.add_argument_group("Data")
group.add_argument("-data_type", default="text",
help="Type of the source input. Options: [text|img].")
group.add_argument("-src", required=True,
help=Source sequence to decode (one line per
sequence))
group.add_argument("-src_dir", default="",
help="Source directory for image or audio files")
group.add_argument("-tgt",
help="True target sequence (optional)")
group.add_argument("-output", default="pred.txt",
help=Path to output the predictions (each line will
be the decoded sequence)
// Options most relevant to summarization.
group.add_argument("-dynamic_dict", action="store_true",
help="Create dynamic dictionaries")
group.add_argument("-share_vocab", action="store_true",
help="Share source and target vocabulary")
group = parser.add_argument_group("Beam")
group.add_argument("-beam_size", type=int, default=5,
help="Beam size")
// Alpha and Beta values for Google Length + Coverage penalty
// Described here: https://arxiv.org/pdf/1609.08144.pdf, Section 7
group.add_argument("-alpha", type=float, default=0.,
help=Google NMT length penalty parameter
(higher = longer generation))group.add_argument("-beta", type=float, default=-0.,
help=Coverage penalty parameter)
group.add_argument("-max_sent_length", type=int, default=100,
help="Maximum sentence length.")
group.add_argument("-replace_unk", action="store_true",
help=Replace the generated UNK tokens with the
source token that had highest attention weight. If
phrase_table is provided, it will lookup the
identified source token and give the corresponding
target token. If it is not provided(or the identified
source token does not exist in the table) then it
will copy the source token)
group = parser.add_argument_group("Logging")
group.add_argument("-verbose", action="store_true",
help="Print scores and predictions for each sentence")
group.add_argument("-attn_debug", action="store_true",
help="Print best attn for each word")
group.add_argument("-dump_beam", type=str, default="",
help="File to dump beam information to.")
group.add_argument("-n_best", type=int, default=1,
help=If verbose is set, will output the n_best
decoded sentences)
group = parser.add_argument_group("Efficiency")group.add_argument("-batch_size", type=int, default=30,
help="Batch size")
group.add_argument("-gpu", type=int, default=-1,
help="Device to run on")
// Options most relevant to speech.