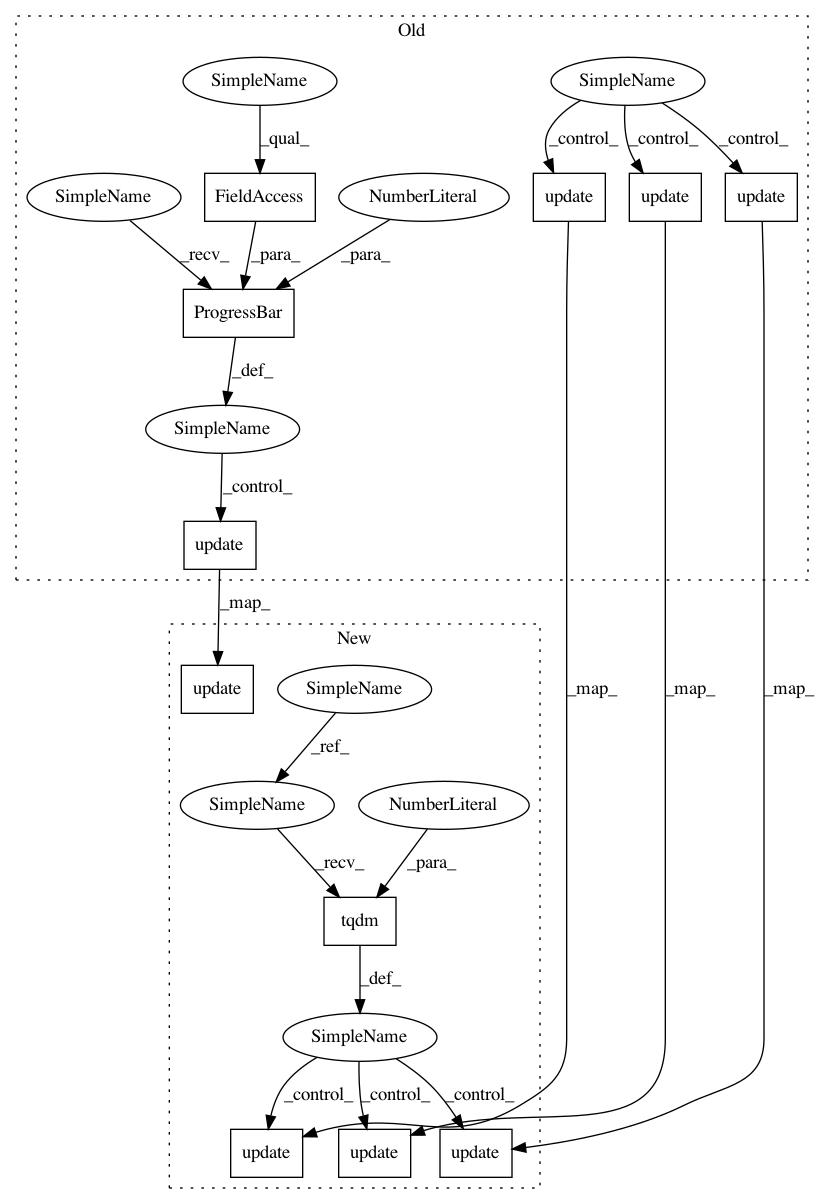
e76a8658b98722c5bb9909a8e4eca61b39dd499f,import_librivox.py,,_download_and_preprocess_data,#,22
Before Change
train_clean_360 = base.maybe_download(filename_of(TRAIN_CLEAN_360_URL), data_dir, TRAIN_CLEAN_360_URL)
bar.update(1)
train_other_500 = base.maybe_download(filename_of(TRAIN_OTHER_500_URL), data_dir, TRAIN_OTHER_500_URL)
bar.update(2)
dev_clean = base.maybe_download(filename_of(DEV_CLEAN_URL), data_dir, DEV_CLEAN_URL)
bar.update(3)
dev_other = base.maybe_download(filename_of(DEV_OTHER_URL), data_dir, DEV_OTHER_URL)
bar.update(4)
test_clean = base.maybe_download(filename_of(TEST_CLEAN_URL), data_dir, TEST_CLEAN_URL)
bar.update(5)
test_other = base.maybe_download(filename_of(TEST_OTHER_URL), data_dir, TEST_OTHER_URL)
bar.update(6)
// Conditionally extract LibriSpeech data
// We extract each archive into data_dir, but test for existence in
// data_dir/LibriSpeech because the archives share that root.
print("Extracting librivox data if not already extracted...")
with progressbar.ProgressBar(max_value=7, widget=progressbar.AdaptiveETA) as bar:
LIBRIVOX_DIR = "LibriSpeech"
work_dir = os.path.join(data_dir, LIBRIVOX_DIR)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "train-clean-100"), train_clean_100)
bar.update(0)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "train-clean-360"), train_clean_360)
bar.update(1)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "train-other-500"), train_other_500)
bar.update(2)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "dev-clean"), dev_clean)
bar.update(3)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "dev-other"), dev_other)
bar.update(4)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "test-clean"), test_clean)
bar.update(5)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "test-other"), test_other)
bar.update(6)
// Convert FLAC data to wav, from:
// data_dir/LibriSpeech/split/1/2/1-2-3.flac
// to:
// data_dir/LibriSpeech/split-wav/1-2-3.wav
//
// And split LibriSpeech transcriptions, from:
// data_dir/LibriSpeech/split/1/2/1-2.trans.txt
// to:
// data_dir/LibriSpeech/split-wav/1-2-0.txt
// data_dir/LibriSpeech/split-wav/1-2-1.txt
// data_dir/LibriSpeech/split-wav/1-2-2.txt
// ...
print("Converting FLAC to WAV and splitting transcriptions...")
with progressbar.ProgressBar(max_value=7, widget=progressbar.AdaptiveETA) as bar:
train_100 = _convert_audio_and_split_sentences(work_dir, "train-clean-100", "train-clean-100-wav")
bar.update(0)
train_360 = _convert_audio_and_split_sentences(work_dir, "train-clean-360", "train-clean-360-wav")
bar.update(1)
train_500 = _convert_audio_and_split_sentences(work_dir, "train-other-500", "train-other-500-wav")
bar.update(2)
dev_clean = _convert_audio_and_split_sentences(work_dir, "dev-clean", "dev-clean-wav")
bar.update(3)
dev_other = _convert_audio_and_split_sentences(work_dir, "dev-other", "dev-other-wav")
After Change
def _download_and_preprocess_data(data_dir):
// Conditionally download data to data_dir
print("Downloading Librivox data set (55GB) into {} if not already present...".format(data_dir))
with tqdm.tqdm(total=7) as bar:
TRAIN_CLEAN_100_URL = "http://www.openslr.org/resources/12/train-clean-100.tar.gz"
TRAIN_CLEAN_360_URL = "http://www.openslr.org/resources/12/train-clean-360.tar.gz"
TRAIN_OTHER_500_URL = "http://www.openslr.org/resources/12/train-other-500.tar.gz"
DEV_CLEAN_URL = "http://www.openslr.org/resources/12/dev-clean.tar.gz"
DEV_OTHER_URL = "http://www.openslr.org/resources/12/dev-other.tar.gz"
TEST_CLEAN_URL = "http://www.openslr.org/resources/12/test-clean.tar.gz"
TEST_OTHER_URL = "http://www.openslr.org/resources/12/test-other.tar.gz"
def filename_of(x): return os.path.split(x)[1]
train_clean_100 = base.maybe_download(filename_of(TRAIN_CLEAN_100_URL), data_dir, TRAIN_CLEAN_100_URL)
bar.update(1)
train_clean_360 = base.maybe_download(filename_of(TRAIN_CLEAN_360_URL), data_dir, TRAIN_CLEAN_360_URL)
bar.update(2)
train_other_500 = base.maybe_download(filename_of(TRAIN_OTHER_500_URL), data_dir, TRAIN_OTHER_500_URL)
bar.update(3)
dev_clean = base.maybe_download(filename_of(DEV_CLEAN_URL), data_dir, DEV_CLEAN_URL)
bar.update(4)
dev_other = base.maybe_download(filename_of(DEV_OTHER_URL), data_dir, DEV_OTHER_URL)
bar.update(5)
test_clean = base.maybe_download(filename_of(TEST_CLEAN_URL), data_dir, TEST_CLEAN_URL)
bar.update(6)
test_other = base.maybe_download(filename_of(TEST_OTHER_URL), data_dir, TEST_OTHER_URL)
bar.update(7)
// Conditionally extract LibriSpeech data
// We extract each archive into data_dir, but test for existence in
// data_dir/LibriSpeech because the archives share that root.
print("Extracting librivox data if not already extracted...")
with tqdm.tqdm(total=7) as bar:
LIBRIVOX_DIR = "LibriSpeech"
work_dir = os.path.join(data_dir, LIBRIVOX_DIR)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "train-clean-100"), train_clean_100)
bar.update(1)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "train-clean-360"), train_clean_360)
bar.update(2)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "train-other-500"), train_other_500)
bar.update(3)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "dev-clean"), dev_clean)
bar.update(4)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "dev-other"), dev_other)
bar.update(5)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "test-clean"), test_clean)
bar.update(6)
_maybe_extract(data_dir, os.path.join(LIBRIVOX_DIR, "test-other"), test_other)
bar.update(7)
// Convert FLAC data to wav, from:
// data_dir/LibriSpeech/split/1/2/1-2-3.flac
// to:
// data_dir/LibriSpeech/split-wav/1-2-3.wav
//
// And split LibriSpeech transcriptions, from:
// data_dir/LibriSpeech/split/1/2/1-2.trans.txt
// to:
// data_dir/LibriSpeech/split-wav/1-2-0.txt
// data_dir/LibriSpeech/split-wav/1-2-1.txt
// data_dir/LibriSpeech/split-wav/1-2-2.txt
// ...
print("Converting FLAC to WAV and splitting transcriptions...")
with tqdm.tqdm(total=7) as bar:
train_100 = _convert_audio_and_split_sentences(work_dir, "train-clean-100", "train-clean-100-wav")
bar.update(1)
train_360 = _convert_audio_and_split_sentences(work_dir, "train-clean-360", "train-clean-360-wav")
bar.update(2)
train_500 = _convert_audio_and_split_sentences(work_dir, "train-other-500", "train-other-500-wav")
bar.update(3)
dev_clean = _convert_audio_and_split_sentences(work_dir, "dev-clean", "dev-clean-wav")
In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 11
Instances
Project Name: NVIDIA/OpenSeq2Seq
Commit Name: e76a8658b98722c5bb9909a8e4eca61b39dd499f
Time: 2018-04-25
Author: vlavrukhin
File Name: import_librivox.py
Class Name:
Method Name: _download_and_preprocess_data
Project Name: NVIDIA/OpenSeq2Seq
Commit Name: e76a8658b98722c5bb9909a8e4eca61b39dd499f
Time: 2018-04-25
Author: vlavrukhin
File Name: import_librivox.py
Class Name:
Method Name: _download_and_preprocess_data