// Actually convert to torch tensors (by accessing everything).
input_ = policy._lazy_tensor_dict(input_)
input_ = {k: input_[k] for k in input_.keys()}
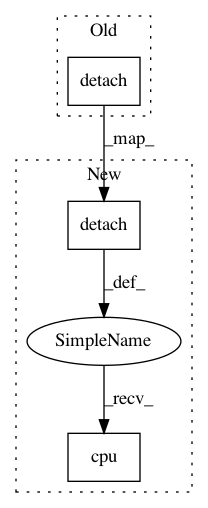
log_alpha = policy.model.log_alpha.detach().numpy()[0]
// Only run the expectation once, should be the same anyways
// for all frameworks.
After Change
// Actually convert to torch tensors (by accessing everything).
input_ = policy._lazy_tensor_dict(input_)
input_ = {k: input_[k] for k in input_.keys()}
log_alpha = policy.model.log_alpha.detach().cpu().numpy()[0]
// Only run the expectation once, should be the same anyways
// for all frameworks.