a0351c62548ebddf5c728ec525ad61a4f7827494,tests/hypermodel/test_preprocessor.py,,test_ngram,#,81
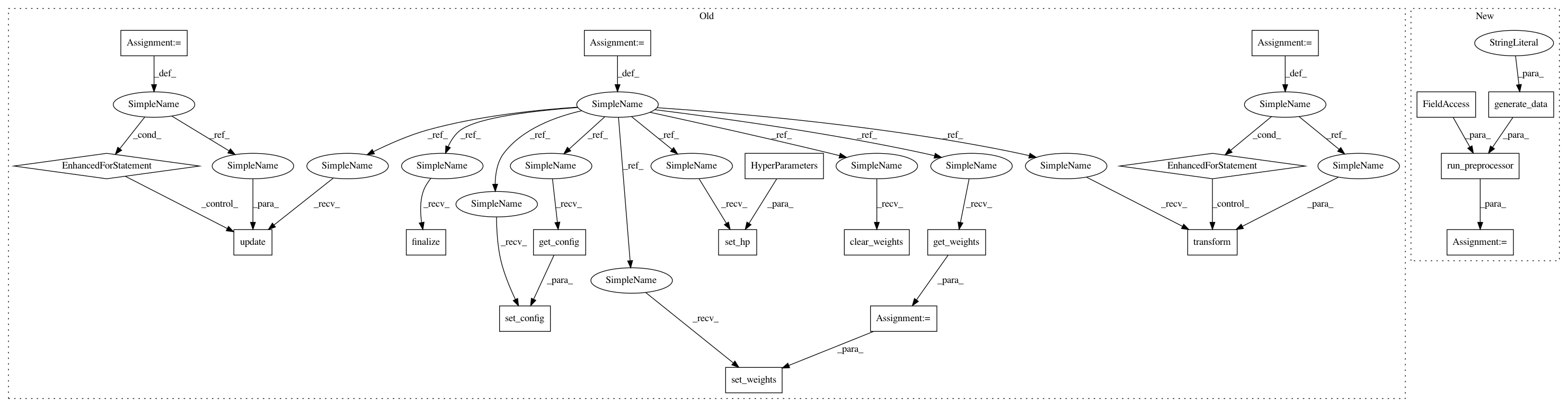
Before Change
texts = ["The cat sat on the mat.",
"The dog sat on the log.",
"Dogs and cats living together."]
tokenize = preprocessor.TextToNgramVector()
dataset = tf.data.Dataset.from_tensor_slices(texts)
tokenize.set_hp(kerastuner.HyperParameters())
for x in dataset:
tokenize.update(x)
tokenize.finalize()
tokenize.set_config(tokenize.get_config())
weights = tokenize.get_weights()
tokenize.clear_weights()
tokenize.set_weights(weights)
for a in dataset:
tokenize.transform(a)
def map_func(x):
return tf.py_function(tokenize.transform,
inp=[x],
Tout=(tf.float64,))
After Change
"The dog sat on the log.",
"Dogs and cats living together."]
dataset = tf.data.Dataset.from_tensor_slices(texts)
new_dataset = run_preprocessor(preprocessor.TextToNgramVector(),
dataset,
common.generate_data(dtype="dataset"),
tf.float32)
assert isinstance(new_dataset, tf.data.Dataset)
def test_augment():
In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 20
Instances
Project Name: keras-team/autokeras
Commit Name: a0351c62548ebddf5c728ec525ad61a4f7827494
Time: 2019-09-29
Author: jhfjhfj1@gmail.com
File Name: tests/hypermodel/test_preprocessor.py
Class Name:
Method Name: test_ngram
Project Name: keras-team/autokeras
Commit Name: a0351c62548ebddf5c728ec525ad61a4f7827494
Time: 2019-09-29
Author: jhfjhfj1@gmail.com
File Name: tests/hypermodel/test_preprocessor.py
Class Name:
Method Name: test_normalize
Project Name: keras-team/autokeras
Commit Name: a0351c62548ebddf5c728ec525ad61a4f7827494
Time: 2019-09-29
Author: jhfjhfj1@gmail.com
File Name: tests/hypermodel/test_preprocessor.py
Class Name:
Method Name: test_sequence