05dcfe15fe94768cd31114486747edfd6381d09c,keras/preprocessing/text.py,Tokenizer,fit_on_texts,#Tokenizer#Any#,75
Before Change
self.document_count = 0
for text in texts:
self.document_count += 1
seq = text_to_word_sequence(text, self.filters, self.lower, self.split)
for w in seq:
if w in self.word_counts:
self.word_counts[w] += 1
else:
After Change
self.document_count = 0
for text in texts:
self.document_count += 1
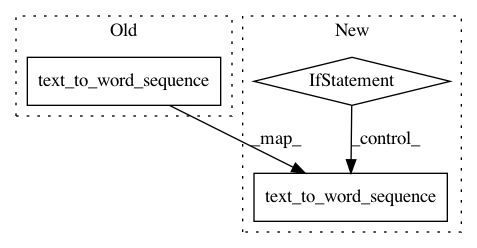
seq = text if self.char_level else text_to_word_sequence(text, self.filters, self.lower, self.split)
for w in seq:
if w in self.word_counts:
self.word_counts[w] += 1
else:
In pattern: SUPERPATTERN
Frequency: 4
Non-data size: 3
Instances
Project Name: keras-team/keras
Commit Name: 05dcfe15fe94768cd31114486747edfd6381d09c
Time: 2016-01-20
Author: wbin00@gmail.com
File Name: keras/preprocessing/text.py
Class Name: Tokenizer
Method Name: fit_on_texts
Project Name: keras-team/keras
Commit Name: 173a1a545954bae38e40f4fb0bde228765a9b059
Time: 2018-02-17
Author: mats@plysjbyen.net
File Name: keras/preprocessing/text.py
Class Name: Tokenizer
Method Name: texts_to_sequences_generator
Project Name: keras-team/keras
Commit Name: 173a1a545954bae38e40f4fb0bde228765a9b059
Time: 2018-02-17
Author: mats@plysjbyen.net
File Name: keras/preprocessing/text.py
Class Name: Tokenizer
Method Name: fit_on_texts
Project Name: keras-team/keras
Commit Name: 05dcfe15fe94768cd31114486747edfd6381d09c
Time: 2016-01-20
Author: wbin00@gmail.com
File Name: keras/preprocessing/text.py
Class Name: Tokenizer
Method Name: texts_to_sequences_generator