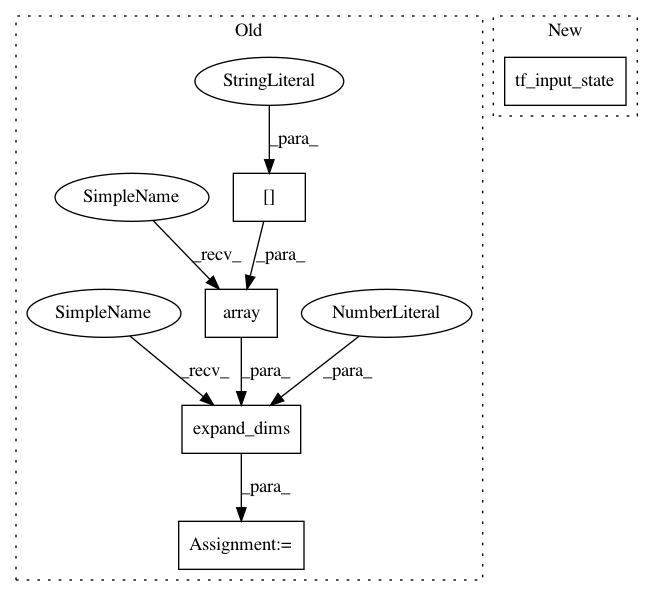
def choose_action(self, curr_state, phase=RunPhase.TRAIN):
assert not self.env.discrete_controls, "DDPG works only for continuous control problems"
// convert to batch so we can run it through the network
observation = np.expand_dims(np.array(curr_state["observation"]), 0)
result = self.actor_network.online_network.predict(observation)
action_values = result[0].squeeze()
if phase == RunPhase.TRAIN:
After Change
def choose_action(self, curr_state, phase=RunPhase.TRAIN):
assert not self.env.discrete_controls, "DDPG works only for continuous control problems"
result = self.actor_network.online_network.predict(self.tf_input_state(curr_state))
action_values = result[0].squeeze()
if phase == RunPhase.TRAIN: