torch.manual_seed(args.seed)
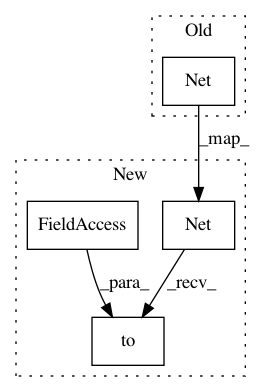
model = Net()
model.share_memory() // gradients are allocated lazily, so they are not shared here
processes = []
for rank in range(args.num_processes):
After Change
torch.manual_seed(args.seed)
mp.set_start_method("spawn")
model = Net().to(device)
model.share_memory() // gradients are allocated lazily, so they are not shared here
processes = []
for rank in range(args.num_processes):