// attention_scores2 = attention_scores2 + co_attention_mask
// Normalize the attention scores to probabilities.
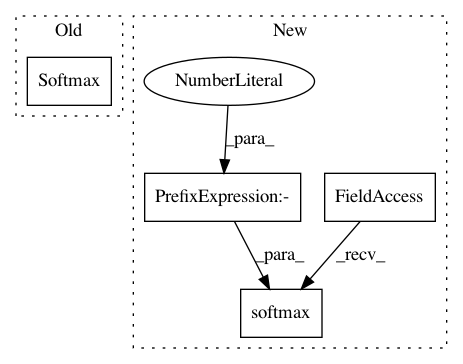
attention_probs2 = nn.Softmax(dim=-1)(attention_scores2)
// This is actually dropping out entire tokens to attend to, which might
// seem a bit unusual, but is taken from the original Transformer paper.
attention_probs2 = self.dropout2(attention_probs2)
After Change
// attention_scores2 = attention_scores2 + co_attention_mask
// Normalize the attention scores to probabilities.
attention_probs2 = nn.functional.softmax(attention_scores2, dim=-1)
// This is actually dropping out entire tokens to attend to, which might
// seem a bit unusual, but is taken from the original Transformer paper.
attention_probs2 = self.dropout2(attention_probs2)