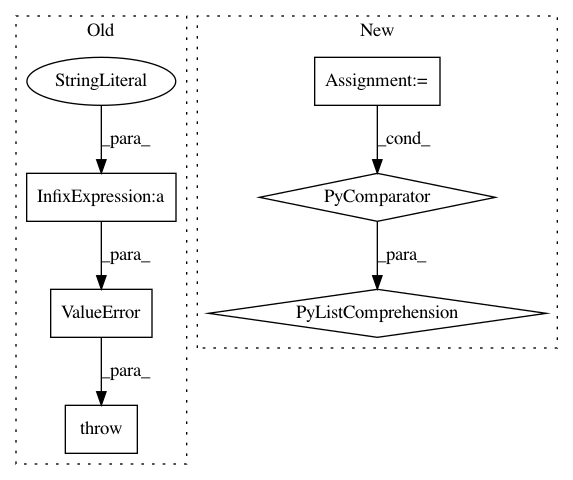
context_vectors = [self._word_vectors[c] for c in context]
if len(context_vectors) == 0: // means we have no context
mfs_sense_id, mfs_prob = self._sense_vectors.get_most_probable_sense(word, self._ignore_case)
return mfs_sense_id, [p for s, p in senses]
// filter context vectors, if aplicable
if self._max_context_words >= 0: