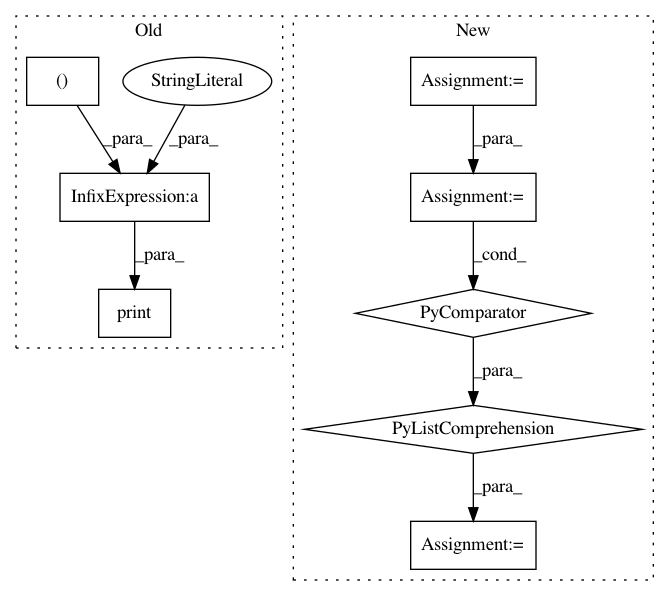
input_files = []
for e in args.input:
if e.startswith("http"):
input_files += [e]
else:
input_files += glob.glob(e)
assert len(input_files) > 0, "No existing media selected for analysis! Bad values provided to -i ({})".format(args.input)
odir = args.output_directory
assert os.access(odir, os.W_OK), "Directory %s is not writable!" % odir
// Do processings
from inaSpeechSegmenter import Segmenter, seg2csv, to_parse
// load neural network into memory, may last few seconds
seg = Segmenter()
// case of a file of files
files = to_parse(input_files)
with warnings.catch_warnings():
warnings.simplefilter("ignore")
//print("processing file %d/%d: %s" % (i+1, len(input_files), e))
base = [os.path.splitext(os.path.basename(e)) for e in files]
base = [base[i][0] for i in range(len(base))]
if len(odir) > 0:
fout = ["%s/%s.csv" % (odir, elem) for elem in base]
seg2csv(seg(files), fout)